on
Hyperparameter Search on a Cluster (Part 1)
- Part 1: Hyperparameter search pipeline
- Part 2: Hyperparameter search pipeline distributed on Exoscale cloud
- Part 3: Employing external programs
The goal of this text is to show a simple hyperparameter on a cluster computer by using Rain. For demonstration purpose we use Tensorflow and it’s MNIST example and we would like to know how accuracy depends on size of hidden layer and dropout. In other words, we would like to generate a prediction accuracy heatmap where rows represent the size of hidden layer and columns represent dropouts.
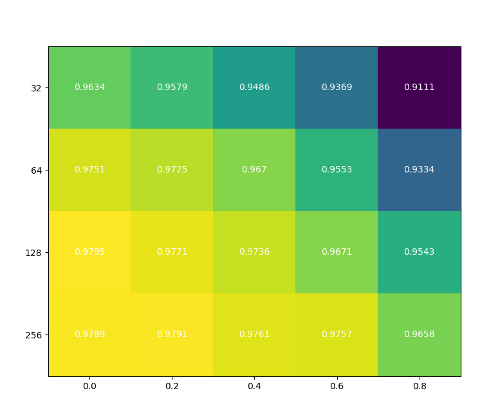
Generating all possible combinations may be quite resource demanding, hence it makes sense to use a cluster of machines. In this blogpost we will guide you through the steps that are required to distribute the computation across the cluster using Rain.
Imports and global variables
At the beginning, we just import Tensorflow, Rain, and define two global variables defining sizes of hidden layers and dropouts that we want to examine.
from rain.client import Client, remote
import tensorflow as tf
import itertools
# Explored sizes of the hidden layer
SIZES = [32, 64, 128, 256]
# Explored values for dropout
DROPOUTS = [0.0, 0.2, 0.4, 0.6, 0.8]
Data loading & training functions
Now we create a loading & training functions. It is basically a parameterized
version of the Tensorflow MNIST wrapped into a Rain decorated functions. We
split data loading and training into two parts, because we want to load the
data only once and train several times. Moreover,
tf.keras.datasets.mnist.load_data() also downloads data if there are not
presented and we want to download data only once and distribute them across the
cluster.
@remote(auto_encode="pickle")
def load_mnist_data(ctx):
return tf.keras.datasets.mnist.load_data()
@remote(auto_encode="pickle")
def train_mnist(ctx, size, dropout, mnist_data):
(x_train, y_train), (x_test, y_test) = mnist_data.load()
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(size, activation=tf.nn.relu),
tf.keras.layers.Dropout(dropout),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, verbose=False)
result = model.evaluate(x_test, y_test, verbose=False)
return result[1]
Rain’s @remote decorator allows to create Rain tasks from a Python function.
Calling such a decorated function does not execute function locally but puts a
task into the execution plan and executes the function somewhere in the cluster.
The decorator argument auto_encode="pickle" says that the result of the
function should be pickled.
Note that in train_mnist we call .load() on mnist_data, because it
arrives in DataInstance wrapper as it is a result of another task.
Method .load() deserializes object or load it from the cache.
Also note that there is parameter ctx. It will hold a reference to
executor’s context. We are not using it in this example, but it is always
passed as the first argument of decorated functions.
Creating execution plan
Now we connect to Rain server. First, we test our program locally, so we use localhost as the server address and port 7210 which is Rain’s default port for clients.
client = Client("localhost", 7210)
Now we create a session. We set the newly create session as the default session, so if not other session is specified, tasks are created within this session.
session = client.new_session("MNIST test", default=True)
The following code creates a tasks. We create one task that loads data by
calling load_mnist_data and array of tasks by calling our function
train_mnist for each combination of hyperparameters. Let us remind that the
actual function is not executed here, only the a task is created into the
execution plan. The @remote decorator also allows to add some extra
arguments, one of them is name that serves for specifying a label for debug
purposes. Note also, that we do not pass ctx argument, since it is
automatically provided when the function is called in an executor.
mnist_data = load_mnist_data()
mnist_tasks = [
train_mnist(size, dropout, mnist_data
name="mnist size={} dropout={}".format(size, dropout))
for size, dropout in itertools.product(SIZES, DROPOUTS)
]
Now we defines what is the result of the computations. In our case, results are
outputs of train_mnist tasks. It is done by .keep() method. It says that
Rain should keep such data objects as long as a session is live (or as
.unkeep() is called). It is necessary, when we want to download results back
to our script.
When a task defines exactly one output (as in our case) then it has the
attribute .output containing the data object produced by the task.
for task in mnist_tasks:
task.output.keep()
So far we have built only a computational plan without its executing. It is time to submit the plan to the server where the actual computation is performed. The submitting is non-blocking operation, when the plan is sent, our Python code continues without waiting on task completion.
session.submit()
Getting results back
The following code downloads results back to our Python code:
accuracies = [task.output.fetch().load() for task in mnist_tasks]
-
Method
fetch()downloads content of the data object to the client; it blocks until the data object is not computed. It returns instance ofDataInstance. -
Method
load()deserializesDataInstance. Content type is stored in objects’ metadata, soload()knows what deserializer to choose. In our case,train_mnistis configured to use pickle the result; therefore, our data are unpickled.
Running local server
Now, we start a local Rain instance to test our implementation:
$ rain start --simple
It starts server and one local governor (working process). Then we can run our Python script; the full source of the program is at the end of text.
The local server can be simly turn off by:
$ killall rain
Running Rain on a cluster is covered in Rain documentation. Running on Exoscale infrastructure is described in the second part of this text.
Dashboard
For monitoring purposes, the server starts dashboard on port 7222. In our local server case, you can see it at http://localhost:7222.
The full code of example
from rain.client import Client, remote
import tensorflow as tf
import itertools
import numpy as np
import matplotlib.pyplot as plt
SIZES = [32, 64, 128, 256]
DROPOUTS = [0.0, 0.2, 0.4, 0.6, 0.8]
@remote(auto_encode="pickle")
def load_mnist_data(ctx):
return tf.keras.datasets.mnist.load_data()
@remote(auto_encode="pickle")
def train_mnist(ctx, size, dropout, mnist_data):
(x_train, y_train), (x_test, y_test) = mnist_data.load()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(size, activation=tf.nn.relu),
tf.keras.layers.Dropout(dropout),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5, verbose=False)
result = model.evaluate(x_test, y_test, verbose=False)
return result[1]
client = Client("localhost", 7210)
session = client.new_session("MNIST test", default=True)
mnist_data = load_mnist_data()
mnist_tasks = [
train_mnist(size, dropout, mist_data,
name="mnist size={} dropout={}".format(size, dropout))
for size, dropout in itertools.product(SIZES, DROPOUTS)
]
for task in mnist_tasks:
task.output.keep()
session.submit()
accuracies = [task.output.fetch().load() for task in mnist_tasks]
def make_heatmap(ax, data):
data = np.array(data).reshape((len(SIZES), len(DROPOUTS)))
im = ax.imshow(data)
ax.set_yticklabels(SIZES)
ax.set_xticklabels(DROPOUTS)
ax.set_yticks(np.arange(len(SIZES)))
ax.set_xticks(np.arange(len(DROPOUTS)))
for j in range(len(DROPOUTS)):
for i in range(len(SIZES)):
text = ax.text(j, i, data[i, j],
ha="center", va="center", color="w")
fig, ax1 = plt.subplots()
make_heatmap(ax1, accuracies)
fig.tight_layout()
plt.show()